Leaderboard
Congratulations to the winners!
| Rank | Team | Overall Score |
|---|---|---|
| 1 | SN Group | 0.78988088 |
| 2 | blcushzz | 0.57718452 |
Introduction
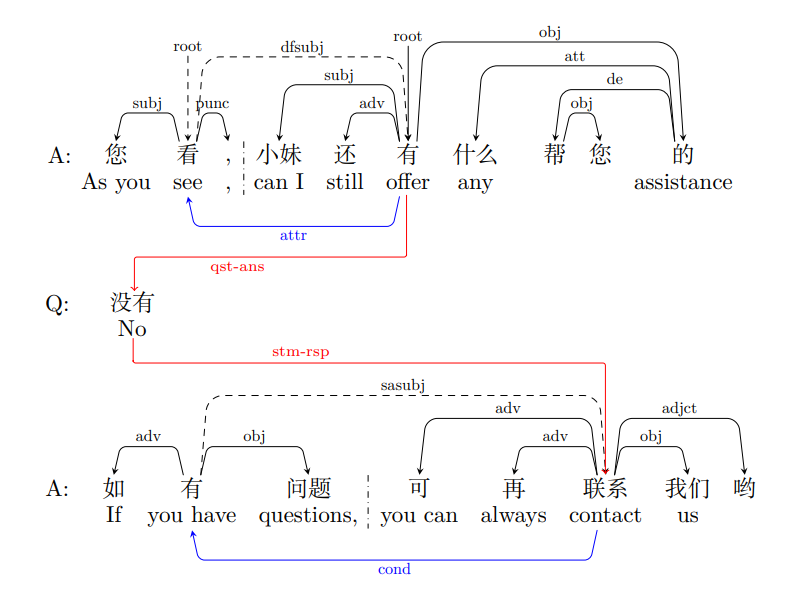
We propose the Dialogue-Level Dependency Parsing (DiaDP) task for Chinese, designed to advance research in dialogue understanding by focusing on fine-grained semantic structure analysis in multi-turn dialogues. This task challenges models to generate accurate dependency structures that capture both inner and inter semantic relationships within Elementary Discourse Units (EDUs). To comprehensively evaluate model performance, the task incorporates inner parsing, which identifies dependencies within individual EDUs using labels such as root, subj, and attr, and inter parsing, which captures dependencies spanning multiple EDUs, focusing on discourse-level relations such as qst-ans and stm-rsp. The example figure illustrates examples of these inner-turn and inter-turn dependency relationships, highlighting the intricate nature of the task. Adopting a few-shot learning setting, we provide a small training set of 50 annotated dialogues to help participants understand the data structure and format. The ultimate goal of this task is to accurately capture these fine-grained semantic relationships, bridging the gap between turn-level and dialogue-level understanding.
Dataset
For the DiaDP task, we provide Chinese Dialogue-level Dependency Treebank (CDDT) consisting of 800 annotated examples as the test set, accompanied by a small 50-sample training set for few-shot learning.
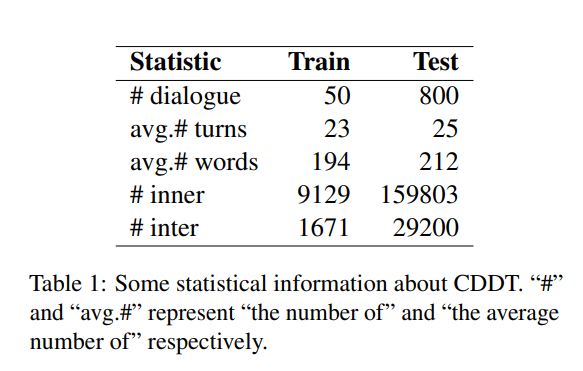
The CDDT statistics are shown in the table with a sample provided below.
[
{
"id": 10374,
"dialog": [
{
"turn": 0, # Dialogue turn index, starting from 0
"utterance": "请 您 稍 等 , 正在 为 您 确认 此前 咨询 内容 。", # Text content, with words separated by spaces
"speaker": "A" # Speaker
},
...
],
"relationship": [
[
"0-0", # Source token, i_j where i is the utterance index and j is the token index (j=0 represents the virtual root of the utterance)
"root", # Dependency relation
"0-1" # Target token, indexed similarly to the source token
],
...
]
}
]
The relationship field includes 21 inner and 19 inter dependency relations.
For detailed definitions of these relations, please refer to the paper[1].
In addition to the training set, we provide various versions of augmented data to further enhance task performance,
along with a simple baseline model. For more details, please visit
this GitHub Repository.
Metrics
Participants are required to construct models that can accurately parse dialogue-level dependency structures. The evaluation of the Dialogue-Level Dependency Parsing task is based on two key metrics:
- Inner UAS and LAS: Evaluates the model’s performance to capture dependencies within EDUs.
- Inter UAS and LAS: Evaluates the model’s performance to capture cross-EDU dependencies.
Submission
Participants can submit at Codabench. The submitted “results.json” should follow the format of the dataset sample. Feel free to contact us at fir430179@gmail.com.
Timeline
Please note: The submission deadline is at 11:59 p.m. (Anywhere on Earth) of the stated deadline date.
Feb 10, 2025:
Training data and participant instruction release for all shared tasks
Apr 6, 2025:
Evaluation deadline for all shared tasks
Apr 10, 2025:
Notification of all shared tasks
Apr 21, 2025:
Shared-task paper submission deadline
Apr 30, 2025:
Acceptance notification of shared-task papers
May 16, 2025:
Camera-ready paper deadline
Award of Top-ranking Participants
Top-ranked participants will also receive a certificate of achievement and will be recommended to write a technical paper for submission to the XLLM workshop of ACL 2025.Organizers
Bin Wang (Harbin Institute of Technology, Shenzhen, China)
Jianling Li (Tianjin University, China)
Hao Fei (National University of Singapore, Singapore)
Meishan Zhang (Harbin Institute of Technology, Shenzhen, China)
Min Zhang (Harbin Institute of Technology, Shenzhen, China)
References
- Jiang, G., Liu, S., Zhang, M., & Zhang, M. (2023). A Pilot Study on Dialogue-Level Dependency Parsing for Chinese. Findings of ACL 2023.
- Zhang, M., Jiang, G., Liu, S., Chen, J., & Zhang, M. (2024). LLM–assisted data augmentation for Chinese dialogue–level dependency parsing. Computational Linguistics.
- Dozat, T., & Manning, C. D. (2017). Deep biaffine attention for neural dependency parsing. In Proceedings of ICLR.
- Guo, P., Huang, S., Jiang, P., Sun, Y., Zhang, M., & Zhang, M. (2022). Curriculum-Style Fine-Grained Adaptation for Unsupervised Cross-Lingual Dependency Transfer. IEEE/ACM Transactions.