Introduction

Overview: Document-level Information Extraction Task.
We introduce the Document-level Information Extraction (DocIE) challenge on this platform. The goal of DocIE is to identify entities, their corresponding mentions, and the relationships between entity pairs within long, unstructured documents. This challenge requires models to process an input document, which consists of a sequence of sentences, and produce output structures that include three key elements: 1) sets of mentions, where each set corresponds to a distinct entity; 2) entity types; and 3) relation triples, which describe the relationships between pairs of entities.
You're welcome to join our Slack community —feel free to ask questions and connect with us!
Dataset
The distribution of domains and source datasets within the DocIE, including 34 domains datasets, is shown in the figure above. The DocIE is a comprehensive dataset that covers a wide range of domains and source datasets, making it a valuable resource for researchers and practitioners in the field of Document-level information extraction.
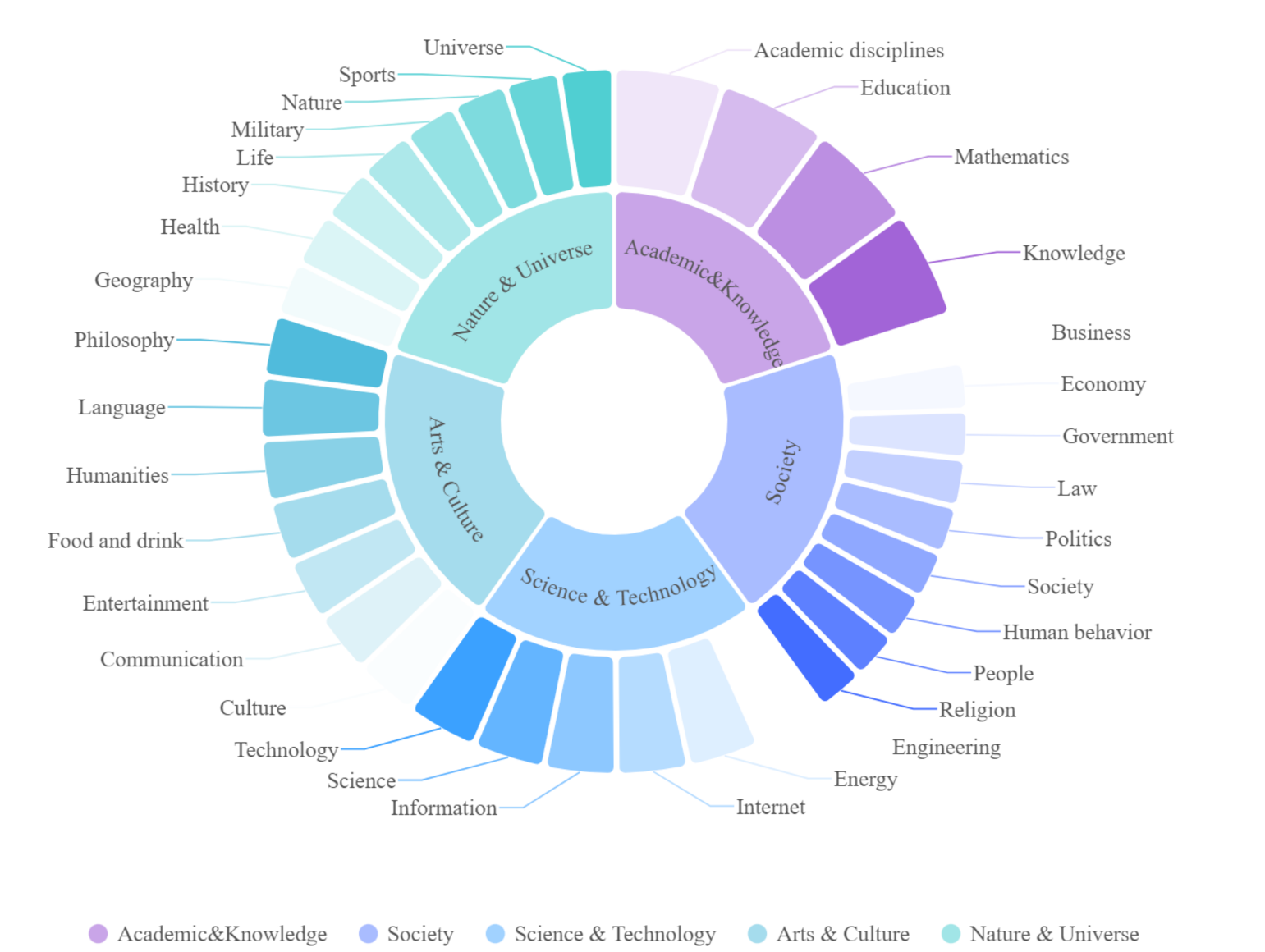
Distribution of different tasks, domains, and source datasets within the DocIE.
Example of a sample:
{
"domain": "Culture",
"title": "The_Triple_Package",
"doc": "The Triple Package: How Three Unlikely Traits Explain the Rise and Fall of Cultural Groups in America is a book published in 2014 by two professors at Yale Law School, Amy Chua and her husband, Jed Rubenfeld. Amy Chua is also the author of the 2011 international bestseller, Battle Hymn of the Tiger Mother.\nAccording to the preface, the authors find that \"certain groups do much better in America than others\u2014as measured by various socioeconomic indicators such as income, occupational status, job prestige, test scores, and so on\u2014 [which] is difficult to talk about. In large part this is because the topic feels racially charged.\" Nevertheless, the book attempts to debunk racial stereotypes by focusing on three \"cultural traits\" that attribute to success in the United States.\nFollowing Battle Hymn of the Tiger Mother in 2011, Chua wrote this book with her husband Jed Rubenfeld after observing a more prevalent trend of students from specific ethnic groups achieving better academic results than other ethnic groups. For example, ..........",
"triplets": [
{
"subject": "The Triple Package",
"relation": "ReviewedBy",
"object": "Colin Woodard"
},
{
"subject": "The Triple Package",
"relation": "Creator",
"object": "Jed Rubenfeld"
},
... ...
],
"entities":[
{
"id": 0,
"mentions": [
"the United States",
"America",
"U.S.",
"American",
"the successful groups in the United States",
"the rest in America",
"the national average",
"the American dream",
"UK"
],
"type": "GPE"
},
{
"id": 1,
"mentions": [
"Yale Law School",
"Yale"
],
"type": "ORG"
},
... ...
],
"label_set": ["ReviewedBy","NominatedFor","InfluencedBy","AwardReceived","HasWorksInTheCollection","Creator","PresentedIn","EthnicGroup","PublishedIn","Affiliation","OwnerOf","InvestigatedBy","CitesWork","HasPart","Acknowledged","DifferentFrom","Follows"],
"entity_label_set":['CARDINAL', 'DATE', 'EVENT', 'FAC', 'GPE', 'LANGUAGE', 'LAW', 'LOC', 'MONEY', 'NORP', 'ORDINAL', 'ORG', 'PERCENT', 'PERSON', 'PRODUCT', 'QUANTITY', 'TIME', 'WORK_OF_ART']
}
The datasets are avaliable on Google Drive.
Challenge Task Definition and Metrtics

Task 1: Named Entity Recognition.
Task-1: Named Entity Recognition (NER) involves identifying named entities within a given text and classifying them into appropriate categories. Participants are expected to develop models that accurately extract both the entities mand their corresponding types. Unlike traditional sentence-level NER tasks, this task requires participants to identify all mentions of each entity within the entire paragraph.

Task 2: Relation Extraction.
Task-2: Relation Extraction(RE) involves identifying the relations between entities within a given text. Participants are expected to develop models that accurately extract both entitiy pairs and its relaion types. Unlike traditional sentence-level RE tasks, this task requires participants to identify all relations of each entity pair within the entire paragraph.
Evaluation
Basic Metric
The F1 score is an important evaluation metric for information extraction tasks, which is calculated by Precision \(P\) and Recall \(R\):$$ P = \frac{TP}{ TP + FP } $$
$$ R = \frac{TP}{TP + FN} $$
$$ F1 = \frac{2 \times P \times R }{ P + R } $$
- \(TP\): True Positive ratio, which indicates the number of samples that were correctly predicted by the model.
- \(FP\): False Positive ratio, which indicates the number of samples that were incorrectly predicted by the model.
- \(FN\): False Negative ratio, which the number of samples that the model's prediction are inconsistent with Ground True .
We will use the F1 score as the main evaluation metric. However, for different settings (strict mode and general mode), there are different criteria for determining whether a sample is correctly predicted, which we will introduce in detail.
Named Entity Recognition
The named entity recognition task can be divided into Entity Identification and Entity Type Classification at a more fine-grained level. In order to evaluate the capabilities of the model more systematically, we set different evaluation indicators for these two aspects:

Example of named entity recognition task. When an entity mention set is judged to be predicted correctly, the value of \(TP_{\text{EI}}\) or \(TP_{\text{EC}}\) increases by 1. Therefore, the final value of \(TP_{\text{EI}}\) or \(TP_{\text{EC}}\) represents the number of correctly extracted entity.
Entity Identification
Participants are required to correctly extract all the entity mentions from the given text. Only all predicted mentions match the ground truth, the sample will be considered correctly predicted. And the value of \(TP_{\text{EI}} \) is the number of samples predicted correctly. Finally, according to the calculation formula of F1 score, \(F1_{EI}\) can be calculated as the evaluation metric of this subtask.
Entity Classification
Participants are required to classify all predicted mentions into the correct entity types. Only all mentions are classify correctly, the sample will be considered correctly predicted. And the value of \(TP_{\text{EC}} \) is the number of samples classify correctly. Finally, according to the calculation formula of F1 score, \(F1_{EC}\) can be calculated as the evaluation metric of this subtask.
Relation Extraction
The evaluation of the relation extraction will be divided into two different settings: general mode and strict mode.

Example of relation extraction task in general mode and strict mode. When a triple is judged to be predicted correctly, the value of \(TP_{\text{REG}}\) increases by 1. Therefore, the final value of \(TP_{\text{REG}}\) represents the number of correctly predicted triplets.
- General Mode: Participants require to accurately extract all entity mentions and their relations in a given text, i.e. accurately predict the relation triplets (head entity mention, relation, tail entity mention). If the head entity mention and tail entity mention are replaced by another mention in the same mention set, we still consider the sample was predicted correctly. \(TP_{\text{REG}}\) is the number of triples predicted correctly in general mode. And based on the above discrimination criteria and the basic metric, \(F1_{REG}\) can be calculated as the evaluation metric of this subtask.
- Strict Mode: Participants require to accurately extract all entities mentions and their relations. In this setting, we strictly compare the difference between the ground true and the predicted results. Therefore, if the head entity mention and tail entity mention are replaced by another mention in the same mention set, we will consider the sample was not predicted correctly. \(TP_{\text{RES}}\) is the number of triples predicted correctly in strict mode. And based on the above discrimination criteria and the basic metric, \(F1_{RES}\) can be calculated as the evaluation metric of this subtask
Baseline
Baseline code and full data will publish as soon as possible.
The evaluation code is available on Github. Participants need to specify the paths for the prediction results file (results.json), the GroundTruth file (reference.json), and the result saving path (scores.json) in the evaluation script (scoring.py), and then run the evaluation script using the following command:
python scoring.py
We utilize GPT-4o and llama3-8b-all as the baseline models for the DocIE challenge. Their performance is shown in the table below, and we have released the prediction code for GPT-4o as the baseline code( baseline_code_gpt4o/gpt4o.py ).
| Category | gpt4o | llama3-8b-all | ||||
|---|---|---|---|---|---|---|
| F1 | P | R | F1 | P | R | |
| Academic_disciplines | 3.25 | 2.78 | 3.9 | 5.07 | 7.23 | 3.9 |
| Business | 1.41 | 1.71 | 1.2 | 4.08 | 13.33 | 2.41 |
| Communication | 10.26 | 13.73 | 8.19 | 2.76 | 6.25 | 1.75 |
| Culture | 7.31 | 9.4 | 5.98 | 5.38 | 8.91 | 3.85 |
| Economy | 2.6 | 2.87 | 2.37 | 7.17 | 14.71 | 4.74 |
| Education | 1.21 | 1.28 | 1.15 | 2.59 | 2.96 | 2.3 |
| Energy | 3.31 | 3.33 | 3.3 | 3.37 | 3.23 | 4.4 |
| Engineering | 3.11 | 2.55 | 3.97 | 4.79 | 6.03 | 3.97 |
| Entertainment | 2.89 | 2.51 | 3.4 | 8.07 | 9.04 | 7.28 |
| Food_and_drink | 0.81 | 0.72 | 0.93 | 3.7 | 5.5 | 2.79 |
| Geography | 2.81 | 4.92 | 1.97 | 8.41 | 14.52 | 5.92 |
| Government | 3.55 | 3.39 | 3.72 | 4.51 | 3.63 | 5.95 |
| Health | 2.73 | 3.23 | 2.36 | 5.69 | 5.19 | 6.3 |
| History | 5.24 | 5.79 | 4.78 | 10.28 | 8.52 | 12.97 |
| Human_behavior | 2.34 | 2.37 | 2.31 | 6.27 | 8.15 | 5.09 |
| Humanities | 2.76 | 3.09 | 2.49 | 1.62 | 4.44 | 0.99 |
| Information | 6 | 12 | 4 | 4.45 | 5.51 | 3.73 |
| Internet | 9.2 | 12.09 | 7.43 | 6.71 | 6.11 | 7.43 |
| Knowledge | 2.15 | 2.26 | 2.05 | 1.63 | 3.85 | 1.03 |
| Language | 7.53 | 8.02 | 7.1 | 4.18 | 8.93 | 2.73 |
| Law | 3.66 | 4.8 | 2.96 | 1.68 | 2.22 | 1.35 |
| Life | 2.72 | 4.55 | 1.94 | 5.84 | 20.59 | 3.4 |
| Mathematics | 9.82 | 11.27 | 8.7 | 10.3 | 15.91 | 7.61 |
| Military | 4.21 | 4.15 | 4.27 | 6.64 | 5.43 | 8.55 |
| Nature | 11.25 | 15.45 | 8.85 | 5.22 | 5.88 | 4.69 |
| People | 0.69 | 0.84 | 0.58 | 3.26 | 2.72 | 4.07 |
| Philosophy | 9.28 | 8.8 | 9.82 | 13.71 | 19.05 | 10.71 |
| Politics | 4.3 | 4.39 | 4.21 | 1.64 | 1.26 | 2.34 |
| Religion | 4.13 | 4.62 | 3.73 | 4.51 | 5.71 | 3.73 |
| Science | 10.33 | 12.09 | 9.02 | 1.49 | 8 | 0.82 |
| Society | 0.95 | 0.92 | 0.98 | 2.26 | 2.7 | 1.95 |
| Sports | 1.17 | 1.29 | 1.07 | 6.76 | 9.17 | 5.35 |
| Technology | 4.85 | 5.19 | 4.55 | 7.72 | 12.05 | 5.68 |
| Universe | 1.6 | 1.65 | 1.55 | 2.61 | 8.33 | 1.55 |
Submission
Our challenge seeks to investigate the domain transfer capabilities of large language models (LLMs) in document-level information extraction (DocIE) tasks, particularly in low-resource settings. To this end, we present a dataset that encompasses document data from many distinct domains. The dataset is divided as follows: 5 domains are designated for training, 2 domains for validation, and the remaining domains are allocated as test sets. Each domain dataset consists of 8 to 10 documents.
Participants may utilize the provided training set to develop their own information extraction models and make predictions on the test set. It is important to note that the use of additional data for training is permitted. Participants are required to apply their trained models to generate predictions on the test set and present the results in the specified format.
Participants need to successfully submit all the following files to be considered valid submissions:
- Prediction result file (results.json): This file should contain the prediction results of the model on the test set, formatted according to the specified requirements.
- Model weight file (*.ckpt, *.bin): Participants are required to provide the trained model weight file. The file should be uploaded to cloud storage, and the corresponding link must be recorded in the link.txt file.
- Executable script file (*.py): An executable script file must be provided, which will be used in conjunction with the submitted model weights to verify the correctness of the provided results. The file should be uploaded to cloud storage, and the corresponding link must be recorded in the link.txt file.
Please sumbit predicted results with a json files "results.json".
{
"Academic_disciplines_0": {
"title": "Anthropocene_Working_Group",
"entities": [
{
"mentions": [
"Industrial Revolution"
],
"type": "event"
},
{
"mentions": [
"HKW"
],
"type": "organization"
},
... ...
],
"triples": [
{
"head": "Max Planck Institute",
"relation": "part of",
"tail": "Max Planck Society"
},
{
"head": "Crawford Lake",
"relation": "country",
"tail": "Canada"
},
... ...
],
},
"Academic_disciplines_1": {
... ...
},
"Academic_disciplines_2": {
... ...
},
... ...
}
Timeline
Please note: The submission deadline is at 11:59 p.m. (Anywhere on Earth) of the stated deadline date.
| Training data and participant instruction release for all shared tasks | February 10, 2025 |
| Evaluation deadline for all shared tasks | |
| Notification of all shared tasks | April 5, 2025 |
| Shared-task paper submission deadline | April 20, 2025 |
| Acceptance notification of shared-task papers | April 30, 2025 |
| Camera ready paper deadline | May 16, 2025 |
Top 2 Teams
- 1st Place: Team qqpprun - Kaifeng Wei, Chengfeng Qiu, Yuke Li, Haoqi Zhu - Yidun AI Lab
- 2nd Place: Team UIT-SHAMROCK - Nguyen Pham Hoang Le, An Dinh Thien, Son T. Luu, Kiet Van Nguyen- University of Information Technology, Vietnam National University, Ho Chi Minh City, Vietnam
Award of Top-ranking Participants
Top-ranked participants in this competition will receive a certificate of achievement and will be recommended to write a technical paper for submission to the XLLM Workshop of ACL 2025.
Prizes: The top-ranking participants will receive the following cash awards:
- 1st Place: $500 USD
- 2nd Place: $300 USD
- 3rd Place: $100 USD
Organizers
Zixia Jia (Beijing Institute for General Artificial Intelligence, Beijing, China)
Zilong Zheng (Beijing Institute for General Artificial Intelligence, Beijing, China)
Shuyi Zhang (Beijing Institute for General Artificial Intelligence, Beijing, China)
Zhenbin Chen (Beijing Institute for General Artificial Intelligence, Beijing, China)
References
[1] Yao, Yuan, et al. "DocRED: A large-scale document-level relation extraction dataset." arXiv preprint arXiv:1906.06127 (2019).
[2] Tan, Qingyu, et al. "Revisiting DocRED--Addressing the False Negative Problem in Relation Extraction." arXiv preprint arXiv:2205.12696 (2022).
[3] Li, Junpeng, Zixia Jia, and Zilong Zheng. "Semi-automatic data enhancement for document-level relation extraction with distant supervision from large language models." arXiv preprint arXiv:2311.07314 (2023).
[4] Gui, Honghao, et al. "Iepile: Unearthing large-scale schema-based information extraction corpus." arXiv preprint arXiv:2402.14710 (2024).
[5] Xue, Lilong, et al. "Autore: Document-level relation extraction with large language models." arXiv preprint arXiv:2403.14888 (2024).