We released the test set for SpeechEE challenge.
Leaderboard
Congratulations to the winners !
| Rank | Team | Overall Score |
| 1 | JUNLP_Soham | 44.6351 |
| 2 | GEDEON | 37.3789 |
Introduction
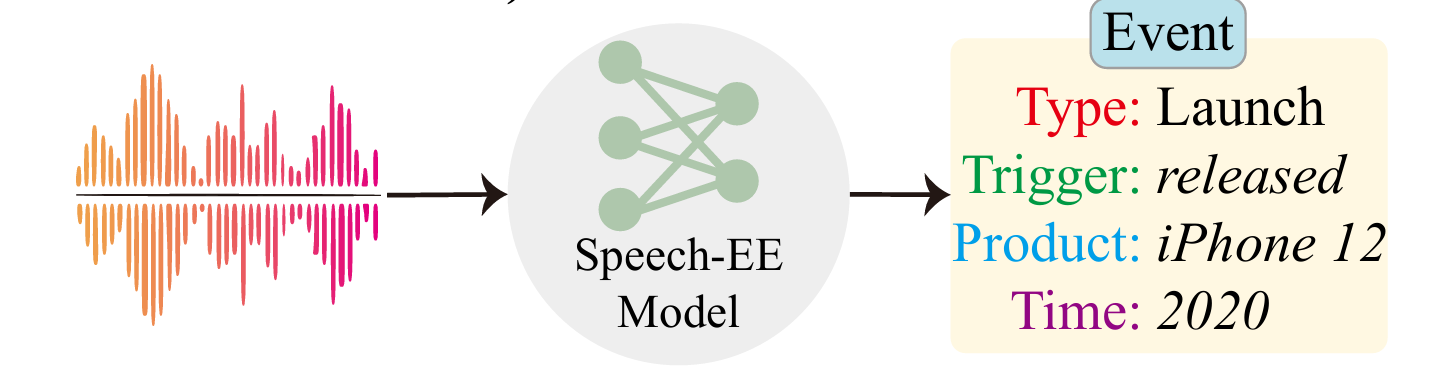
Overview: SpeechEE Task.
We propose the Speech Event Extraction (SpeechEE) challenge on the XLLM platform. Unlike traditional textual event extraction, SpeechEE aims to detect event triggers and arguments directly from audio speech, even when transcripts are unavailable. The SpeechEE is defined as: Given a speech audio input consisting of a sequence of acoustic frames, the goal is to extract structured event records comprising four elements: 1) the event type, 2) the event trigger, 3) event argument roles, and 4) the corresponding event arguments.
The challenge contains three subtasks, from easy to hard.
Challenge Task Definition and Metrtics
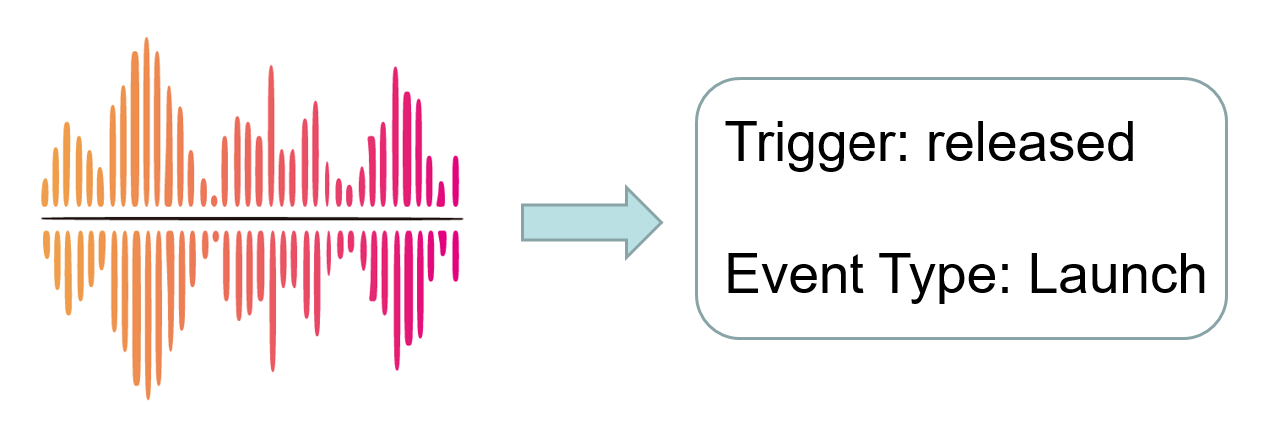
Task 1: Event Detection.
Task-1: Event Detection aims to identify event trigger words and classify them into corresponding event types. Participants are required to develop models that can accurately extract the event triggers. A trigger is considered correctly extracted if both the trigger mention and the event type match the reference. The evaluation metric for this sub-task is the F1 score.
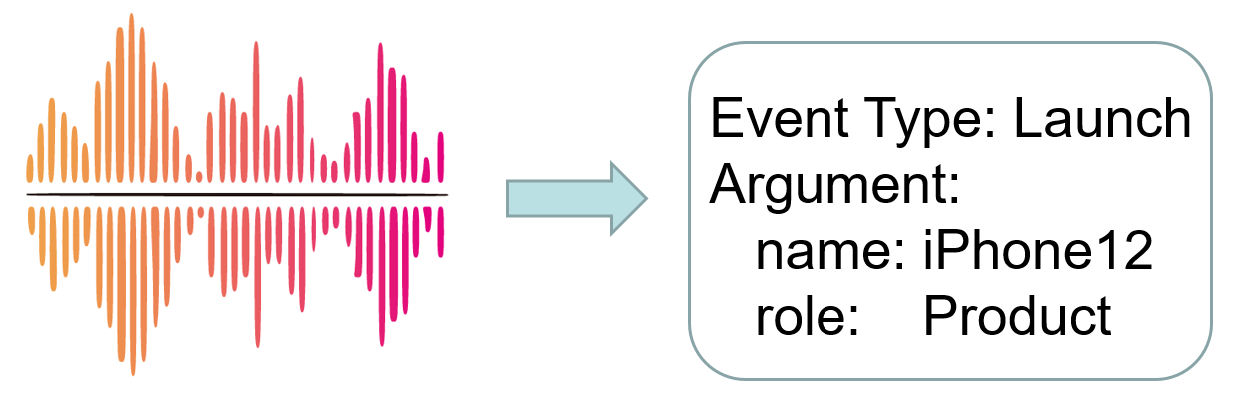
Task 2: Event Argument Exraction.
Task-2: Event Argument Exraction aims to the identify the event argument and classify the argument role. An argument is considered correctly extracted if its event type, argument role, and argument mention all match the reference. The evaluation metric for this sub-task is the F1 score.
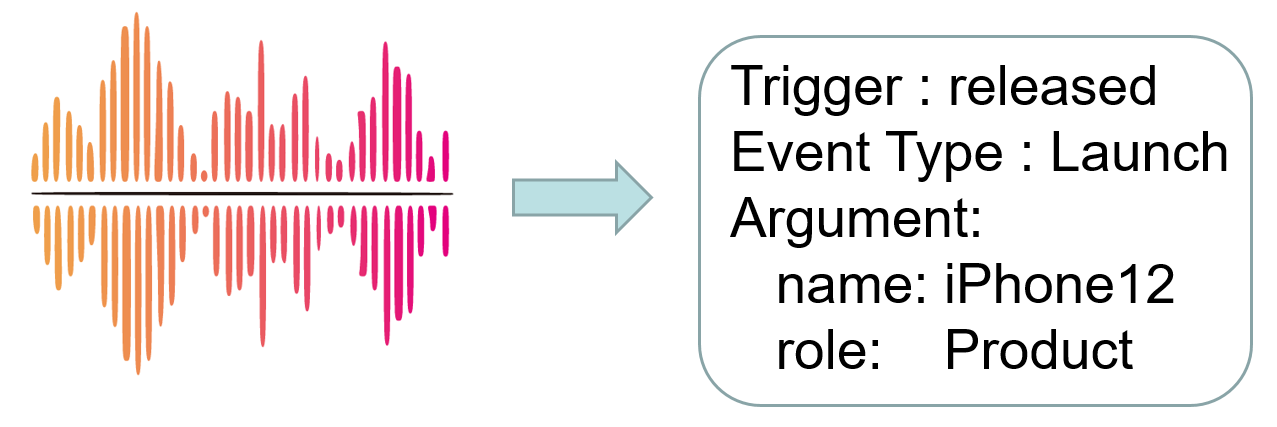
Task 3: Event Quadruple Extraction.
Task-3: Event Quadruple Extraction aims to extract the complete event record quadruple including event trigger, event type, argument role and argument mention. The evaluation metric for this sub-task is the F1 score.
Evaluation
The F1 score is computed using precision (P) and recall (R), which are calculated as follows:
P = TP / ( TP + FP )
R = TP / ( TP + FN )
F1 = 2 * P * R / ( P + R )
where TP, FP, and FN represent specific items that are used to calculate the F1 score in the context of a Confusion_matrix. In particular, when computing the micro-F1 score, TP corresponds to the number of predicted tuple that match exactly with those in the gold set.Finally, we use the following score for ranking:
overall score=0.3*Task1+0.3*Task2+0.4*Task3
We provide python scripts for evaluation, please refer to the baseline codes "/challenge/scoring.py".
Dataset
The dataset for this challenge is derived from ACE2005-EN+. It is a benchmark dataset for event extraction in the English language. ACE2005-EN+ extended the original ACE05-EN data by considering multi-token event triggers and pronoun roles.
This dataset contains 33 event types and 22 argument roles, with 19217 training data, 901 developing data and 676 testing data. The detailed information is recorded in the baseline codes "/challenge/event-schema.json".
Example of a sample:
{"id": "train-3", "event": [{"trigger": "landed", "type": "Transport", "arguments": [{"name": "boat", "role": "Vehicle"}, {"name": "men", "role": "Artifact"}, {"name": "shores", "role": "Destination"}]}]}
The datasets (audio) are avaliable on Google Drive and the label json files are in the baseline codes "/challenge/data/ACE05EN".
Timeline
Please note: The submission deadline is at 11:59 p.m. (Anywhere on Earth) of the stated deadline date.
| Training data and participant instruction release for all shared tasks | February 10, 2025 |
| Evaluation deadline for all shared tasks | April 6, 2025 |
| Notification of all shared tasks | April 10, 2025 |
| Shared-task paper submission deadline | April 21, 2025 |
| Acceptance notification of shared-task papers | April 30, 2025 |
| Camera ready paper deadline | May 16, 2025 |
Submission
Please sumbit predicted results with a json files "results.json".
[
{
"id": "test-0",
"event": [{
"trigger": "advance",
"type": "Transport",
"arguments": [{
"name": "elements",
"role": "Artifact"
}, {
"name": "city",
"role": "Origin"
}, {
"name": "Baghdad",
"role": "Destination"
}]
}]
},
{
"id": "test-1",
"event": [{
...
}]
},
...
]
Participants can submit at Codabench.
We will review the submissions publish the ranking here. Feel free to contact us at fir430179@gmail.com.
Baseline
Link to the code SpeechEE code
Award of Top-ranking Participants
Top-ranked participants in this competition will receive a certificate of achievement and will be recommended to write a technical paper for submission to the XLLM Workshop of ACL 2025.
Organizers
Bin Wang (Harbin Institute of Technology, Shenzhen, China)
Hao Fei (National University of Singapore, Singapore)
Meishan Zhang (Harbin Institute of Technology, Shenzhen, China)
Min Zhang (Harbin Institute of Technology, Shenzhen, China)
Yu Zhao (Tianjin University, China)
References
[1] Wang, B., Zhang, M., Fei, H., Zhao, Y., Li, B., Wu, S., ... & Zhang, M. (2024, October). SpeechEE: A Novel Benchmark for Speech Event Extraction. In Proceedings of the 32nd ACM International Conference on Multimedia (pp. 10449-10458).
[2] Ying Lin, Heng Ji, Fei Huang, and Lingfei Wu. 2020. A Joint Neural Model for Information Extraction with Global Features. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7999–8009, Online. Association for Computational Linguistics.